
Fable 5 Is the First Claude Above Opus. Here's the Day-One Math Before You Switch.
For three years, the Claude lineup has been a tidy poem: Haiku, Sonnet, Opus — small, medium, large. Yesterday Anthropic broke the meter. Claude Fable 5 is a new tier above Opus: a public, safeguarded version of the Mythos-class frontier model Anthropic has so far only run in restricted settings. It costs double what Opus 4.8 does, it tops every benchmark Anthropic published, and as of this week it's the model behind my Claude Code sessions — I flipped the default the day it landed. Full disclosure: the agent that helped me research this post was running on it.
This is a day-one look, which means the usual caveat applies: nobody has run this thing in production for a month yet, including me. What I can give you is what actually shipped, what changed in the API (there's one gotcha that will 400 your requests), and the honest math on whether a model at 2x the price earns its keep.
What actually shipped
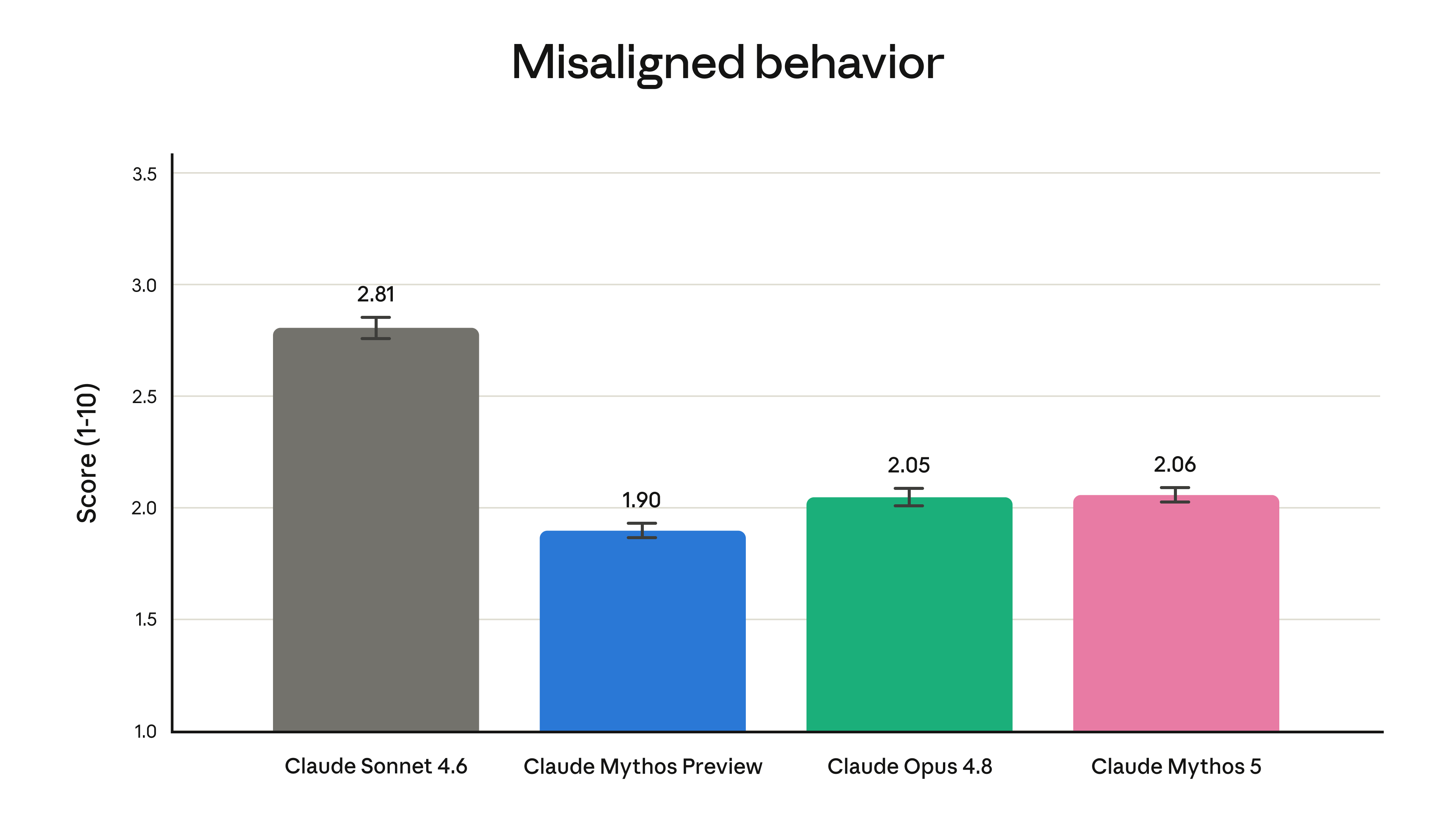
Two models, same brain. Claude Mythos 5 is the unrestricted version, deployed through something called Project Glasswing in collaboration with the US government. Claude Fable 5 is the same underlying model with safeguards bolted on for the rest of us. The safeguard mechanism is the genuinely novel part: when a query touches a high-risk area — cybersecurity, biology, chemistry, model distillation — Fable 5 doesn't just refuse. It silently falls back and serves you a response from claude-opus-4-8 instead. Anthropic says this triggers in under 5% of sessions on average. Hold that thought; it matters for builders, and I'll come back to it.
Availability has a deadline attached. Fable 5 is included in Pro, Max, Team, and seat-based Enterprise plans only until June 22 — after that it drops out of subscriptions and requires usage credits, until capacity catches up. So the next twelve days are effectively a free trial window for subscribers. Use them.
The numbers
Pricing: $10 per million input tokens, $50 per million output — exactly double Opus 4.8's $5/$25, and less than half what Anthropic charged for the Mythos Preview. Context window is 1M tokens at standard pricing, max output 128K.
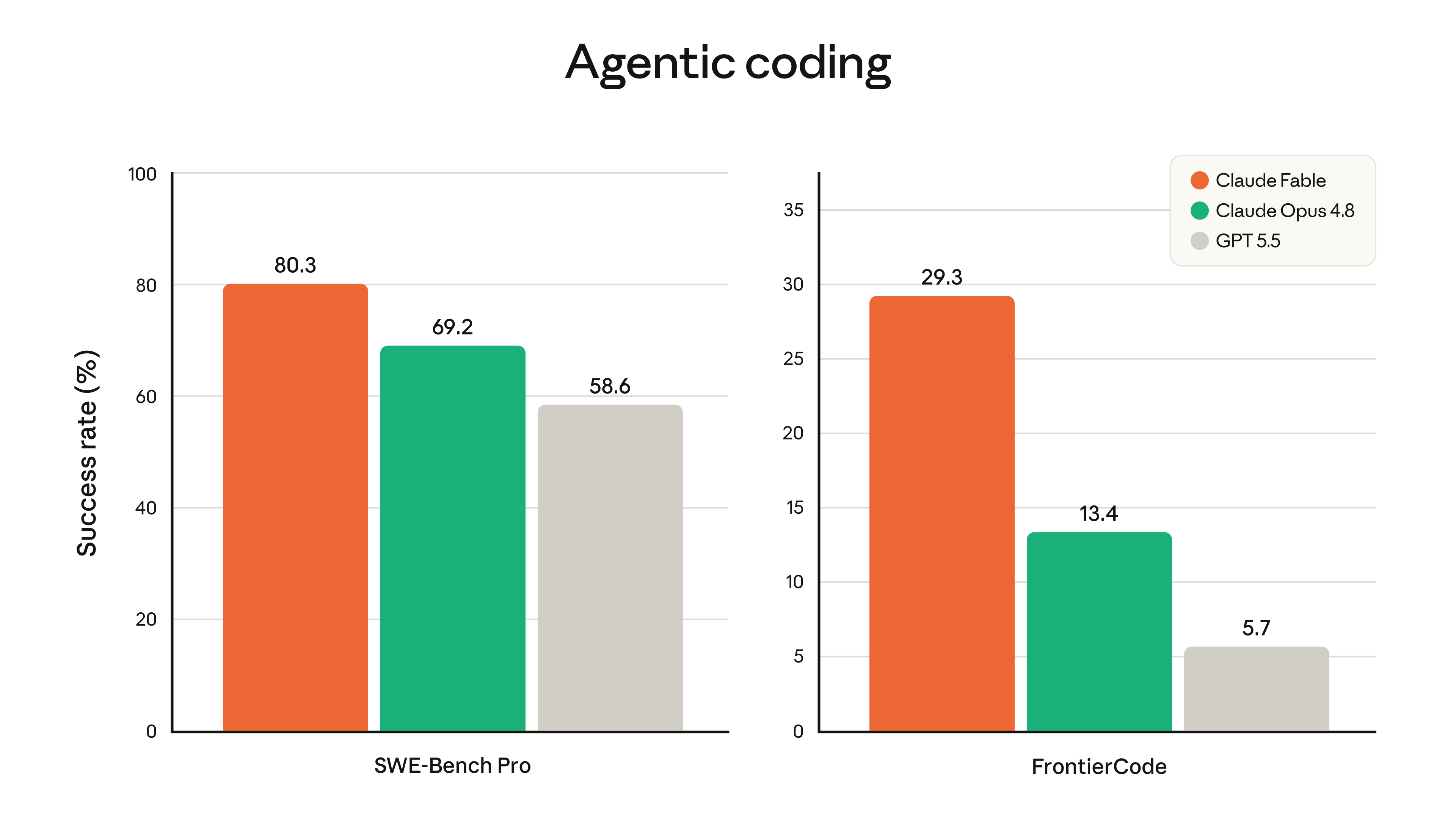
Benchmarks: 80.3% on SWE-Bench Pro, against GPT-5.5's 58.6%. That's not an incremental gap; that's a tier gap. Andrej Karpathy called it "a major-version-bump-deserving step change forward" and described the practical difference well: you can hand it more ambitious tasks than you're used to, and "the model 'gets it' and it will just go."
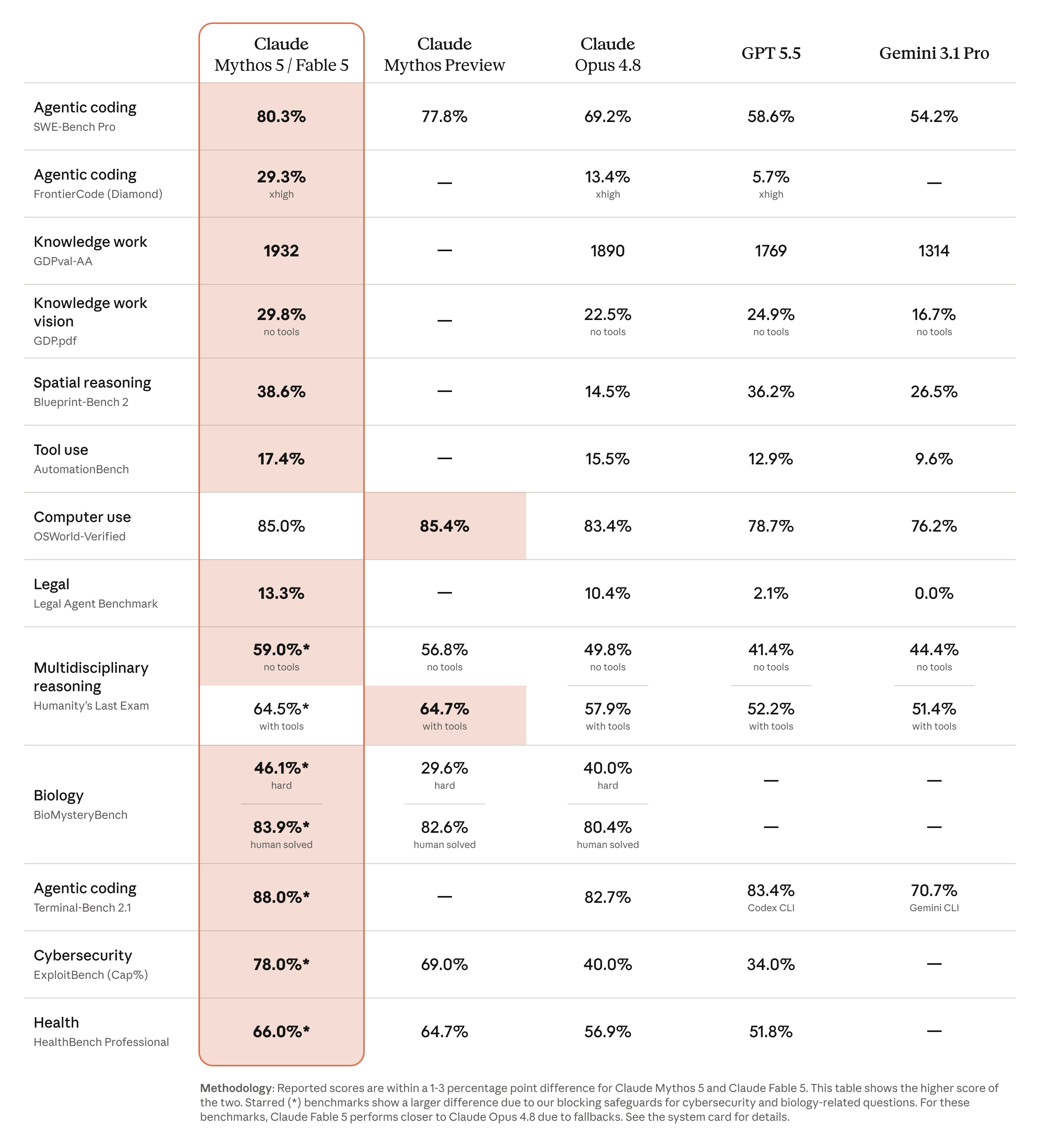
More from Anthropic's own eval table: Fable 5 posts the highest FrontierCode score among frontier models at medium effort, the highest score any model has recorded on Hebbia's finance benchmark, and it's the first model to break 90% on Anthropic's analytics benchmark — a ten-point jump over Opus 4.8. The strangest entry: with persistent file-based memory enabled, Fable scored 3x better than Opus 4.8 at playing Slay the Spire. Long-horizon memory is apparently no longer the bottleneck.
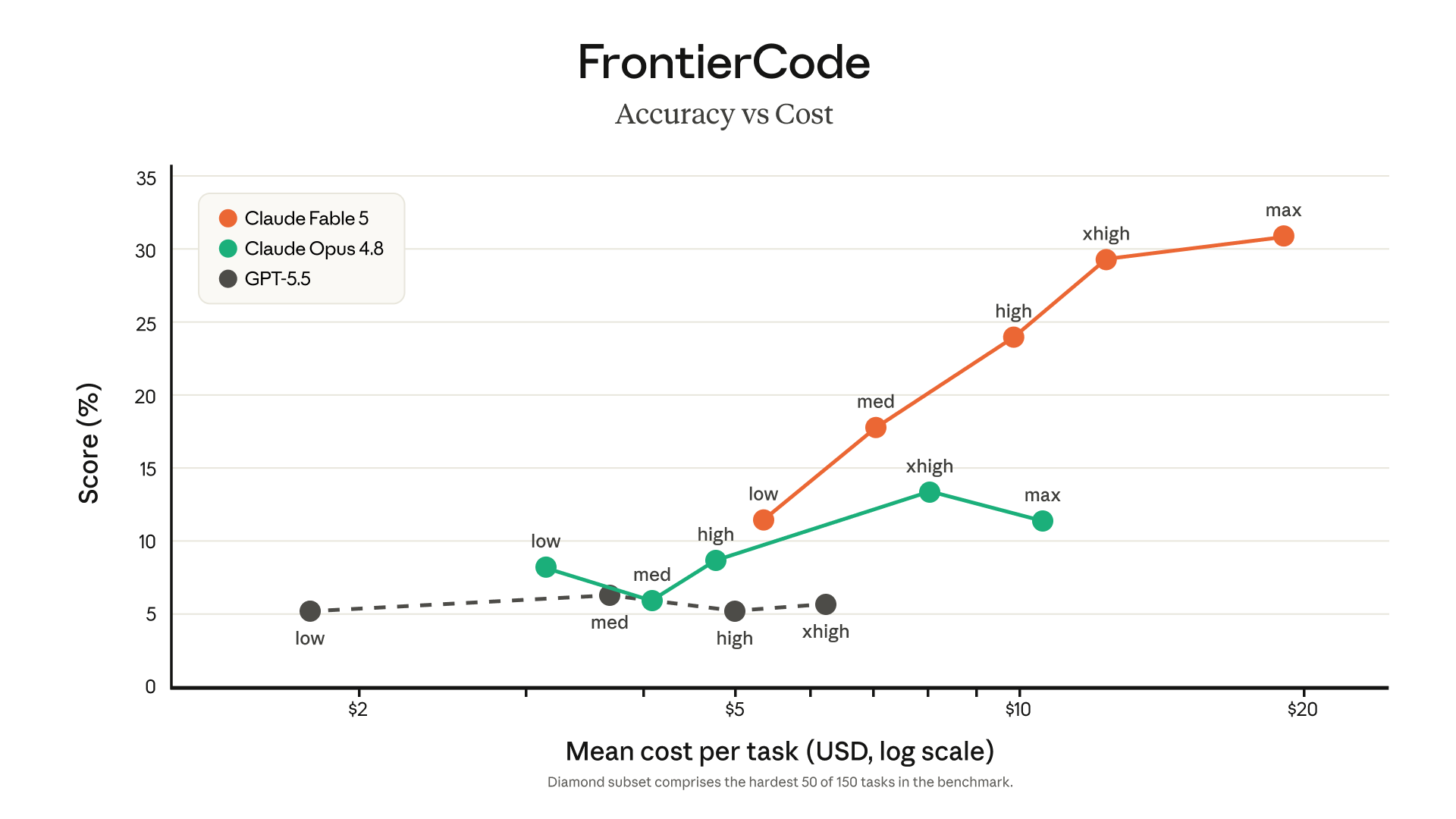
The flagship anecdote: Stripe reportedly ran a codebase-wide migration across 50 million lines of code in a single day — work they estimated at two months for a team. Launch-day anecdotes from design partners deserve skepticism by default, but it's directionally consistent with what the long-horizon agentic benchmarks claim.
All charts in this post are from Anthropic's launch announcement.
The API surface — and the gotcha
The model ID is claude-fable-5 — no date suffix. It inherits the strict request surface Anthropic has been converging on since Opus 4.7: adaptive thinking is the only thinking mode, and the sampling knobs are gone entirely. temperature, top_p, top_k, budget_tokens, and assistant-turn prefills all return a 400.
But Fable adds one new breaking change of its own, and it's sneaky: an explicit thinking: {type: "disabled"} — which Opus 4.7 and 4.8 still accept — returns a 400 on Fable 5. If you want thinking off, you omit the parameter entirely. Any codebase that toggles thinking with an explicit disabled state will break on the model swap, and the error message won't make the fix obvious.
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
const response = await client.messages.create({
model: "claude-fable-5",
max_tokens: 16000,
thinking: { type: "adaptive" }, // the only on-mode Fable accepts
output_config: { effort: "high" }, // low | medium | high | xhigh | max
messages: [{ role: "user", content: "..." }],
});
// All of these 400 on claude-fable-5:
// temperature: 0.7
// top_p: 0.9
// thinking: { type: "enabled", budget_tokens: 8000 }
// thinking: { type: "disabled" } // <- new in Fable; just omit itTwo more notes for anyone migrating from Opus 4.8. First, switching models invalidates your entire prompt cache — the first request on Fable rebuilds it from scratch, so expect a one-time cost bump on cached workloads. Second, Fable's minimum cacheable prefix is 2,048 tokens, down from Opus 4.8's 4,096 — prompts that silently failed to cache on Opus may start caching on Fable. Effort levels, task budgets, compaction, structured outputs, and the 1M context all carry over unchanged. It's already generally available in GitHub Copilot and on Amazon Bedrock.
The honest part
The fallback is a determinism problem. Under 5% of sessions sounds small until you put it in production terms: roughly one in twenty sessions may silently get a different model than the one you're paying for. If you're building anything where you benchmark, eval, or debug against a specific model's behavior, "sometimes it's secretly Opus 4.8" is a real confound. Karpathy already flagged that the launch-day safeguards are "configured to be a little too trigger happy," and security-adjacent work — which, after last week's post-mortem, is half of what I do — sits exactly in the fallback zone. If your domain is cybersecurity, test before you commit.
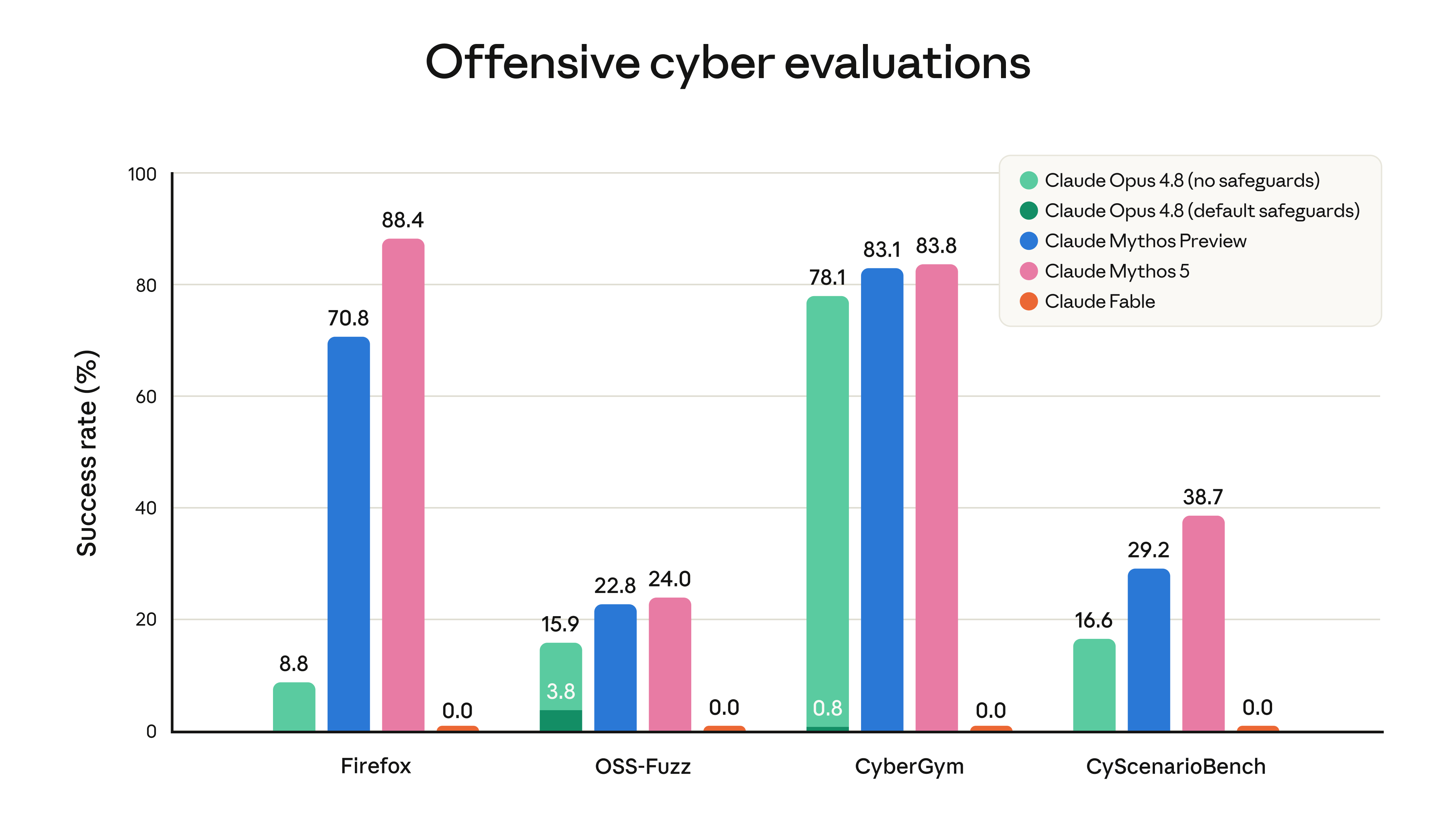
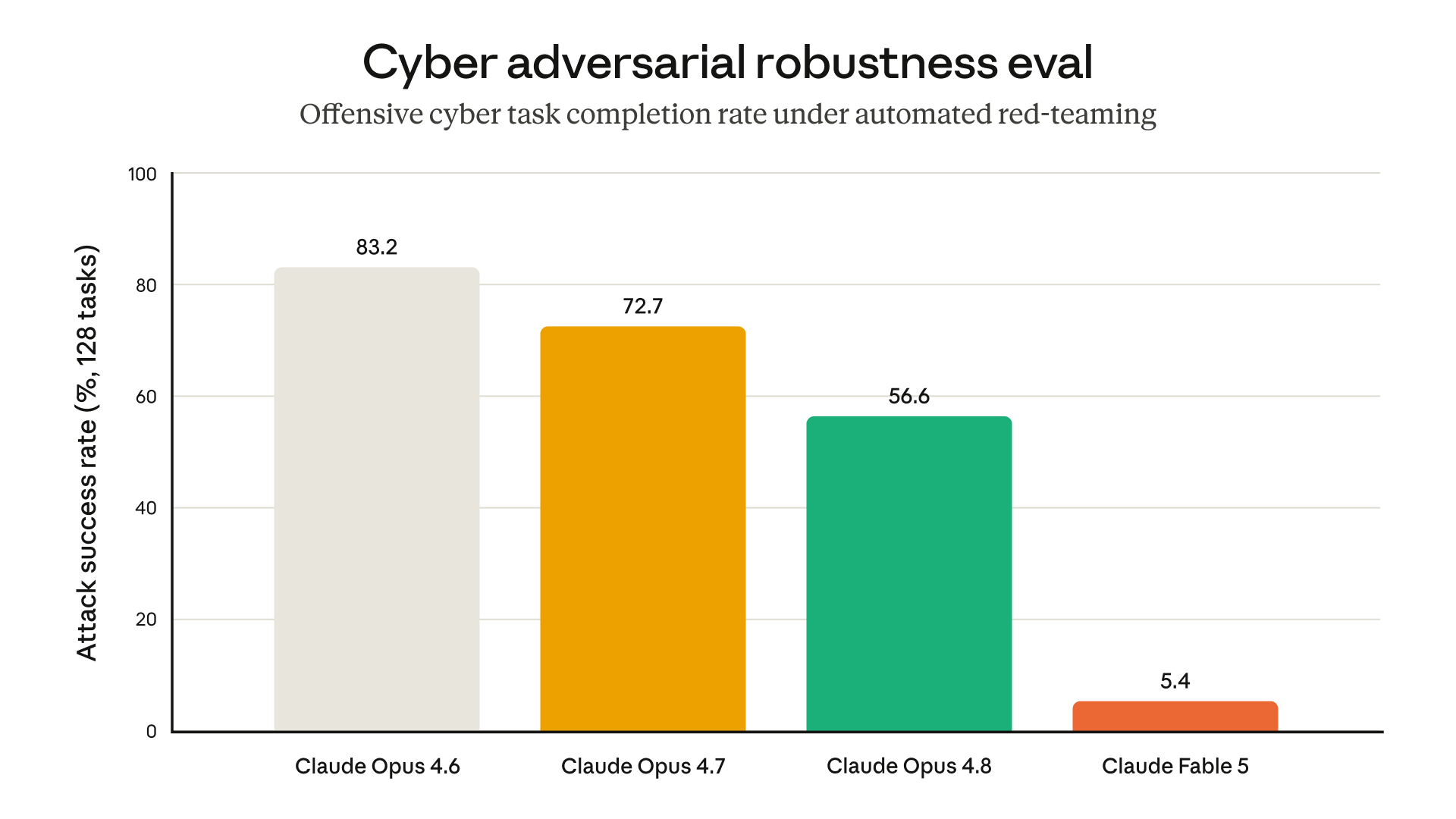
The flip side of the trigger-happy classifiers: this is also the most jailbreak-resistant model Anthropic has shipped, holding up across 400 turns of automated red-teaming. Pick your trade-off.
The 2x sticker price is not the real price — it could be better or worse. Anthropic and early customers claim Fable finishes tasks in fewer turns and fewer tokens, so a job at 2x the per-token rate can land closer to Opus cost than the sticker suggests. That matches the Opus 4.7→4.8 pattern, where higher up-front reasoning reduced total turn count on agentic work. But "can land closer" is doing a lot of work in that sentence, and nobody outside Anthropic has published independent cost-per-task numbers yet. Until someone does, budget for 2x and treat anything better as a bonus.
The subscription cliff is real. If you wire your workflow around Fable 5 this week on a Pro or Max plan, on June 22 it becomes a metered add-on. Anthropic says it will return to subscriptions "when capacity is sufficient," with no date attached. Don't build a dependency on a model you might lose access to in two weeks — keep your Opus 4.8 path working.
Verdict
The model itself is the easiest part of this verdict: it's the best thing you can currently point Claude Code at, and the difference is noticeable on exactly the tasks Karpathy described — the big, ambitious, underspecified ones where previous models needed hand-holding. For interactive coding on a subscription plan, switch today and enjoy the window.
For the API, my rule for now: Fable 5 for long-horizon agentic work where one model-run replaces hours of engineering time — migrations, deep refactors, research agents — because there the 2x rate is noise against the value. Opus 4.8 stays the default for production pipelines, anything requiring deterministic model identity, and anything security-flavored until the fallback behavior is better understood. Sonnet 4.6 still wins everything high-volume. I'm running my PR-reviewer agent on both Fable and Opus for the next two weeks with identical inputs; cost-per-task numbers in a follow-up, whichever way they land.
More writing